在二月初時,國科會表示為了建置主權 AI,需要完整、高可信度的資料庫,並直指要鬆綁著作權法,以將政府的開放資料用在 AI 研發,來解決缺乏訓練資料的問題,此提議引起學界譁然。
為了推動 AI,修法放寬聽起來勢在必行,但修訂著作權法可能牽一髮而動全身,要如何顧及著作權人的權益?目前業界用於訓練 AI 的資料,除了使用無著作權,以及合法授權的資料外,大多還需加入一些灰色地帶的資料,例如網路新聞、部落格文章、論壇留言等,這些其實都屬於未授權之使用。若進行修法,勢必要考量是否會有連帶影響。

與現行著作權法規的衝突
目前已有許多 AI大廠因為著作權議題而被告上法院,例如:
- 通用AI 模型/服務:OpenAI、Microsoft、Meta、Google、Anthropic
- 音樂:Suno、Udio
- 圖像:Stability AI、DeviantArt、Midjourney
- 影片:Runway AI
在這些案件中,AI 廠商大多主張自己不是直接複製或散佈受著作權(又稱版權)保護的作品,而是將這些作品作為「原料」,用於訓練 AI 理解資料的模式和結構,最終生成全新的、與原始作品不同的輸出。
另外,許多人倡議目前的著作權法規並未充分考慮到 AI 技術的特殊性,因此必須調整或重新詮釋著作權法。然而這樣的論點真的能夠說服法院嗎?
其實,訓練 AI 並不是讓電腦去「讀」網路上的公開資料,而是要將資料下載後,才能人為標註或編輯資料,再餵給模型進行訓練;因此,明顯涉及著作權法上的「重製」。
能主張「合理使用」?
大部分身陷訴訟的 AI 大廠,是以「合理使用」作為主要的抗辯方式。在台灣,要能成功主張合理使用,必須依據四個因素進行綜合判斷:
(1) 利用之目的及性質,包括係為商業目的或非營利教育目的。
(2) 著作之性質。
(3) 所利用之質量及其在整個著作所占之比例。
(4) 利用結果對著作潛在市場與現在價值之影響。
由於 AI 模型有相當大的商業價值,且可能完整複製了許多資料,也會大幅度影響原著作的市場(已經有相當多產業受到影響),是否能夠主張合理使用,是相當有疑問的。政府想要修著作權法,是否也是為了先幫 AI 廠商「拆彈」?
著作人權益已然受損
目前大多數 AI 廠商,都是先做再說,在法院作出判決前,能衝多遠是多遠。通常企業也會表示,要訓練出能用的 AI 模型,必須使用大量資料,而他們很難在事先獲得所有資料的授權,再進行模型訓練,而這會導致 AI 技術的發展停滯。
也常有人說,訓練 AI 就像人類讀書,只是換成電腦來讀,為什麼就會侵權?這樣的類比其實有著很大的謬誤,其中主要的差別在於「人類閱讀」與「訓練 AI 」的目的及結果是完全不同的。
聽音樂、讀書、或觀賞繪畫作品,通常不是為了產生一個類似的作品,而是想要享受、學習、或研究。但「生成式 AI 」的目的只有一個,就是「生成」。而且閱聽眾在獲得生成的成果後,很可能就不再需要使用或購買原本的作品了。
另外,當使用 AI 生成內容時,使用者無法得知內容是源自於哪些人的創作。當原始作者的貢獻無法被彰顯時,就是對作者姓名表示權的一種間接侵犯。這是目前較難依靠技術解決的問題,因為內容在模型中已經轉為向量的形式,自然無法追溯到原始作品。
雖然有些 AI服務會在生成的文章中標註資料來源,例如 Google 的 NotebookLM 會引述使用者上傳的文件,ChatGPT 或 Perplexity 也都可以搜索網路資訊,並結合模型中本身的資訊做出回答,但這些被引述的文獻其實是都是另外取得的資料來源,無法解決原始訓練資料中的溯源問題。
大廠已經積極取得合法資料授權
在著作權訴訟進行的同時,AI 也早已開始砸錢買資料。下表為媒體所報導的授權交易:
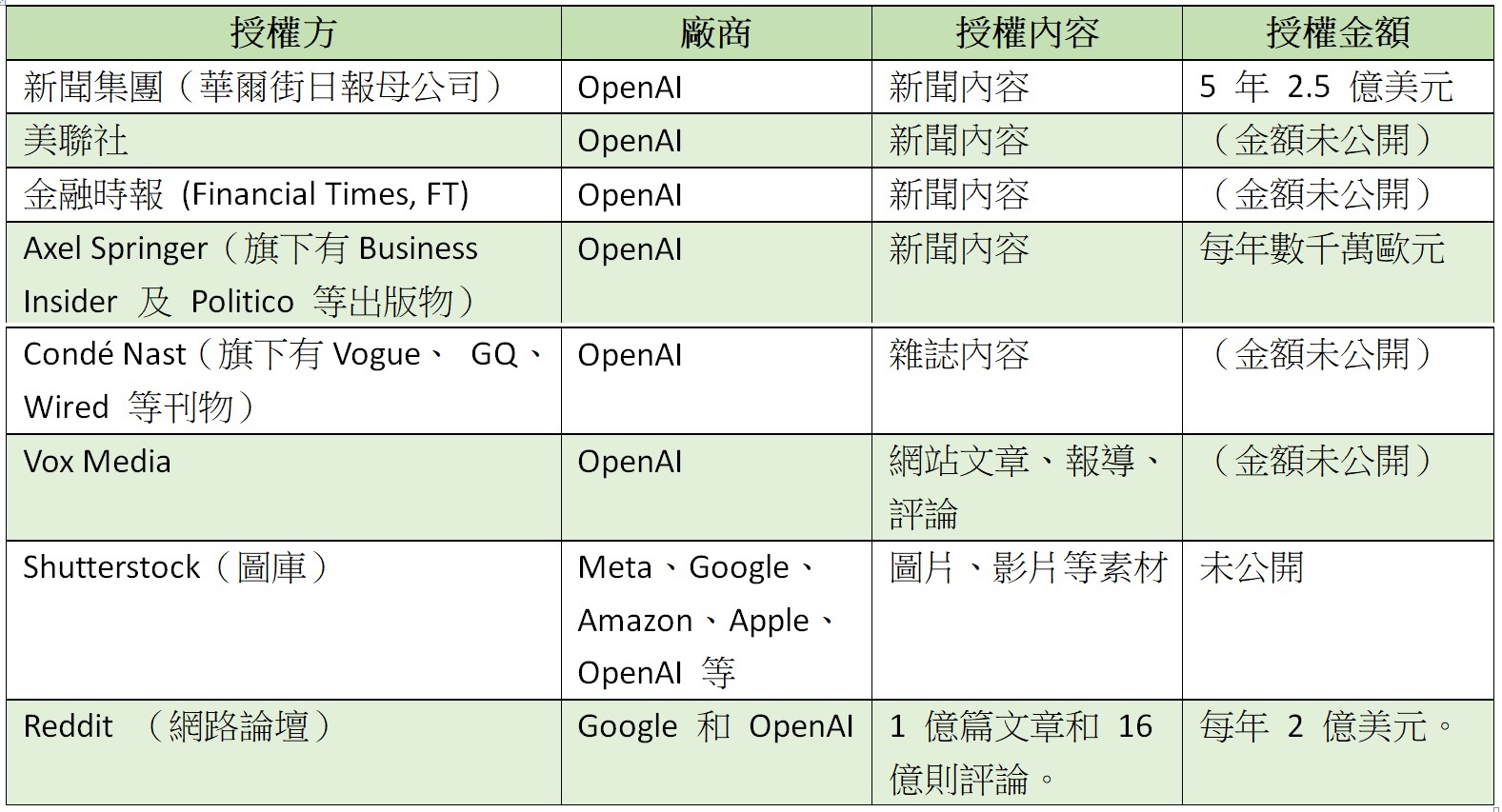
這些授權大部分是由 OpenAI 所簽訂並發布,宣示意味濃厚,其中與新聞集團的交易金額高達 2.5 億美元。這些大廠當然也不是一開始就選擇購買資料。OpenAI 最初只是個非營利的研究機構,在資料使用上彈性較大。但在 ChatGPT 成功商業化後面臨諸多訴訟,自然只能開始向第三方取得資料授權。
Meta自從被告上法院後,不斷有內部文件被公開,外界也因此才了解,Meta 當年發現追趕不上 OpenAI 後,開始無視內部人員的警告,公然抓取盜版書籍作為訓練資料。Google 則是目前訴訟較少的公司,或許是因為資料較為乾淨,但作為 AI 實力最雄厚的公司,這可能也就是一直在 OpenAI 之後苦苦追趕的原因之一。
著作權法向來是隨著科技發展而逐漸調整,但不代表它一定得「順應潮流」。在網路泡沫年代,Napster 曾經橫掃音樂產業,但兩年後就因為侵犯著作權而急速殞落。當各國法院判決一一出現後,哪一家 AI 廠商會因此掉隊?能拿捏好風險與商業利益的廠商,才有辦法笑到最後。筆者猜想許多大廠可能都預備了「低風險」的模型。一旦法院的判決站在著作權人一方,就可以馬上更換。或許之前 ChatGPT 被報導突然「變笨」的狀況,也與此有關。
屬於台灣的中文語料仍然嚴重不足
無論要發展主權 AI,或鼓勵廠商打造 AI 產品,優質的訓練資料都是不可或缺的。然而台灣政府或 AI 廠商,似乎都力不從心。以國科會的TAIDE模型為例,來自民間出版社或媒體的資料居然只有下表所列:
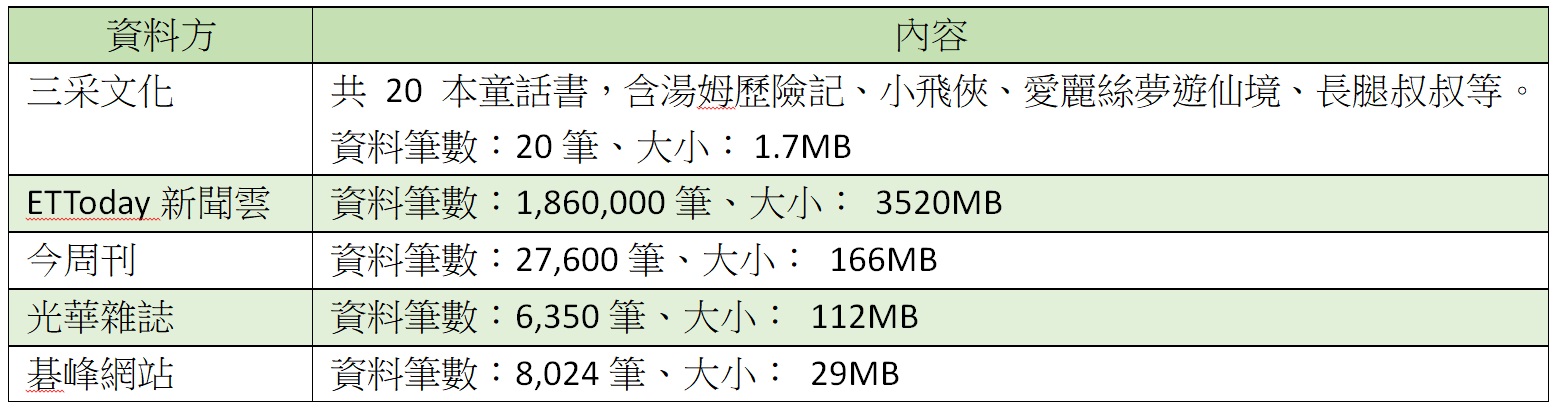
僅以這些以 MB 作為單位的資料量,配合公部門資料,似乎不太可能打造出主權 AI。更重要的是,政府一直都大聲疾呼要增加訓練資料,但經過一兩年,這份清單卻幾乎沒有新增。
行政院已編列百億級的預算發展 AI,但外界一直以來都關注算力的硬體,不清楚有多少被用來合法取得訓練資料。因此現在說要用修改著作權法的方式來解決,也沒有說明相關配套,在學界及創作者的耳中自然特別刺耳。
完整配套可參考國外做法
在 AI已經成為軍備競賽的大環境下,人人都想搶先。雖然各國政府皆不敢大力要求 AI 馬上合規,但仍陸續有國家出現一些指引,試圖在 AI 發展與創作者權益間取得平衡。對於台灣來說,筆者建議可參酌歐盟及日本的做法,例如:
(1) 公開訓練資料來源,並定期接受稽查。
(2) 開放使用公開資料訓練 AI,但必須給予著作權人opt-out(選擇退出)的機會,如果能建立類似 AI 稅的回饋機制會更好。
(3) 不可有明顯違法的行為,例如使用盜版資料庫及蓄意繞過付費牆(paywall)取得資料。
會如此倡議,是因為許多 AI 模型已經開源,現實上已經不可能阻止任何人自建模型使用,因此堅守公開資料需要授權已幾乎失去意義。這自然會損害創作者的權益,因此必須搭配 opt-out 及 AI 稅等機制,以平衡公眾利益。而公開訓練資料是檢核 AI 廠商是否有落實自我管理的前提,當然也是無法迴避的義務。
這樣的方案對於 AI 廠商已經相當寬容,因為大部分著作權人可能沒有心力對自己的作品進行opt-out。且未來若公眾慢慢習慣利用 AI 獲取資訊,可能會逼迫著作權人要想盡辦法讓自己的內容被 AI 抓取及訓練(就像網站要做 SEO 以出現在 Google 搜尋結果一樣)。AI 服務的滲透度,會大幅度影響產業的格局及大眾所認知的「公眾利益」,這也是 AI 廠商甘冒風險也要不斷衝刺的原因之一。
參考資料:
責任編輯:李淑蓮
【本文僅反映專家作者意見,不代表本報立場。】