





DeepSeek最新推出的R1模型,要求能以更低成本、更高效率的方式,提供ChatGPT等模型的替代方案,在高科技圈掀起一股热潮,更曾让辉达(Nvidia)创下史上最大单日跌幅,市值蒸发近6,000亿美元。过去普遍认为,要打造出强大的AI模型,就必须投入数百亿美元购买运算设备,DeepSeek的异军突起,打破了AI模型开发遥不可及的既定观念。

成立于2023年的深度求索(DeepSeek),是一间目标要打造「通用人工智能」(AGI)的人工智能公司,让机器可以理解人类语言、生成文字、进行对话,并协助解决各种复杂的问题。2024年底,DeepSeek发布了DeepSeek-R1和DeepSeek-V3两款AI大语言模型,并于2025年1月推出DeepSeek-R1的聊天机器人程序。在美国禁止高阶芯片售往中国的情况下,DeepSeek成立短短不到一年,能以相对极低的训练成本,推出号称与ChatGPT同等级的AI大语言模型DeepSeek,在全球AI圈引起了广泛关注。
AI产业走向高效发展、芯片需求出现变化
AI行业过去依赖扩大模型、增加数据和提升硬件效能来发展,但成本与效率就成为发展AI模型的挑战。TrendForce指出,DeepSeek采用蒸馏模型(Model Distillation)技术,压缩大型模型以提升推理速度并降低硬件需求,同时充分发挥 NVIDIA Hopper降规版芯片的效益,最大化运算资源利用。DeepSeek的成本优势来自高效能硬件选择、新型蒸馏技术及API开源策略,不仅优化技术与商业应用的平衡,也展现AI产业走向高效发展的趋势。
DeepSeek近期连续发表DeepSeek-V3、DeepSeek-R1等AI模型,将促使终端客户未来更审慎评估投入AI基础设施的合理性,采用更具效率的软件运算模型,以降低对GPU等硬件的依赖。云解决方案提供商(CSP)则可能扩大采用自家特定应用集成电路(ASIC)的基础设施,以降低建置成本。因此,2025年以后,产业对GPU AI芯片或半导体实际需求可能出现变化。
TrendForce表示,全球AI服务器(Server)市场自2023年起快速成长,预期2025年占整体Server出货比例将逾15%,至2028年有望接近20%。近年大型CSP业者应AI训练需求积极扩建,自2025年起将扩展重心至边缘AI推理,除了采用NVIDIA Blackwell等新一代GPU平台,AWS等也加大开发自家ASIC力道,以提升成本效益、满足特定AI应用需求。中国CSP和DeepSeek等相关AI业者面对美国芯片出口禁令,着重于开发更高效的AI芯片或算法,以促进AI需求和应用的多元发展。
更多竞争者加入战局
DeepSeek横空出世打乱AI模型的发展步调,对传统 AI巨头造成庞大的压力,一方面也暴露出AI模型的开发盲点,不过微软、Meta、Google等科技巨擘都明确表示,不会改变持续投入AI发展的计划。
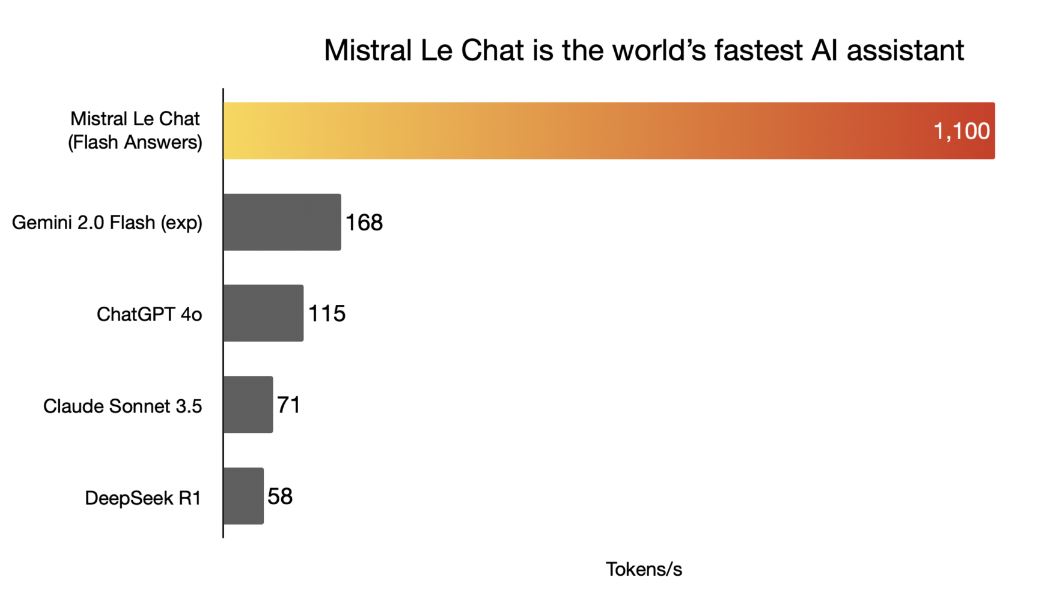
Nvidia的重要竞争者、AI芯片新创商Cerebras Systems,2月6日宣布携手法国开源AI新创Mistral AI推出聊天机器人「Le Chat」,Cerebras表示,Le Chat的推论速度每秒超过1,100个符元(token),比ChatGPT 4o、Claude Sonnet 3.5和 DeepSeek R1等热门AI模型快10几倍,号称是全球速度最快的AI助理,击败OpenAI和DeepSeek[1]。
除了DeepSeek之外,其他中国公司近期也纷纷推出AI模型一较高下,腾讯开发了由文本到视频的模型Hunyuan-Large,不仅超过了Meta开源的最新、最大模型LLama3.1 – 405B,并在数学、日常推理、文本生成等方面具有优异表现[2]。字节跳动1月22日发布了豆包大模型1.5(Doubao-1.5-pro),并展示在知识、程序代码、推理、中文等多个权威评测基准上,综合得分优于GPT-4o、Claude 3.5 Sonnet 等一流模型[3];阿里云在大年初一宣布「通义千问」旗舰版模型Qwen2.5-Max全新升级,阿里巴巴称其性能超越了DeepSeek在2024年12月底发布的DeepSeek-V3[4]。
中国AI市场未来两大走向
TrendForce指出,在美国芯片禁令持续的情况下,预期中国AI市场将朝两个重点方向发展。首先,AI相关业者将加速投入自主AI芯片或供应链发展,中国大型CSP业者等除了尽量采购目前尚可取得辉达特供中国的H20芯片之外,未来将加速扩大发展自有ASIC应用于自家数据中心。其次,中国将利用既有的互联网基础优势,以软件补足硬件缺陷,像是DeepSeek打破常规,改采蒸馏技术强化AI应用机会即是。
整体而言,预期未来美国政府可能对中国相关AI或半导体禁令趋严下,迫使欲投入AI发展的中国业者加速发展自有AI芯片或高带宽存储器(High Bandwidth Memory,HBM)等硬件。尽管其效能不及NVIDIA等GPU方案,但若主要为满足中国市场自用数据中心基础建设,单位芯片效能已非唯一考虑。此外,DeepSeek等业者近期朝AI多模态模型发展,力求在更低的训练成本下,于特定应用领域达到类似效能,以加速实现商用化。
尽管存在诸多争议,但DeepSeek仍以低成本和高性价比产品,成功挑战OpenAI、Google等AI巨头,象征着中国在 AI 领域的快速发展,加上全球许多新创业者前仆后继进入AI模型市场,都将改写全球AI市场的竞争格局。
备注:
[1] 2025/2/6,Cerebras : Cerebras brings instant inference to Mistral Le Chat.
[2] 2024/11/6,腾讯网:「腾讯放大招,超Meta!史上参数最大,开源专家混合模型」。
[3] 2025/1/22,字节跳动:「豆包大模型1.5正式发布,全面上线火山方舟」。
[4] 2025/1/29,阿里云:「新年第一弹,Qwen2.5-Max来了!」。
|








